Explore MovieNet
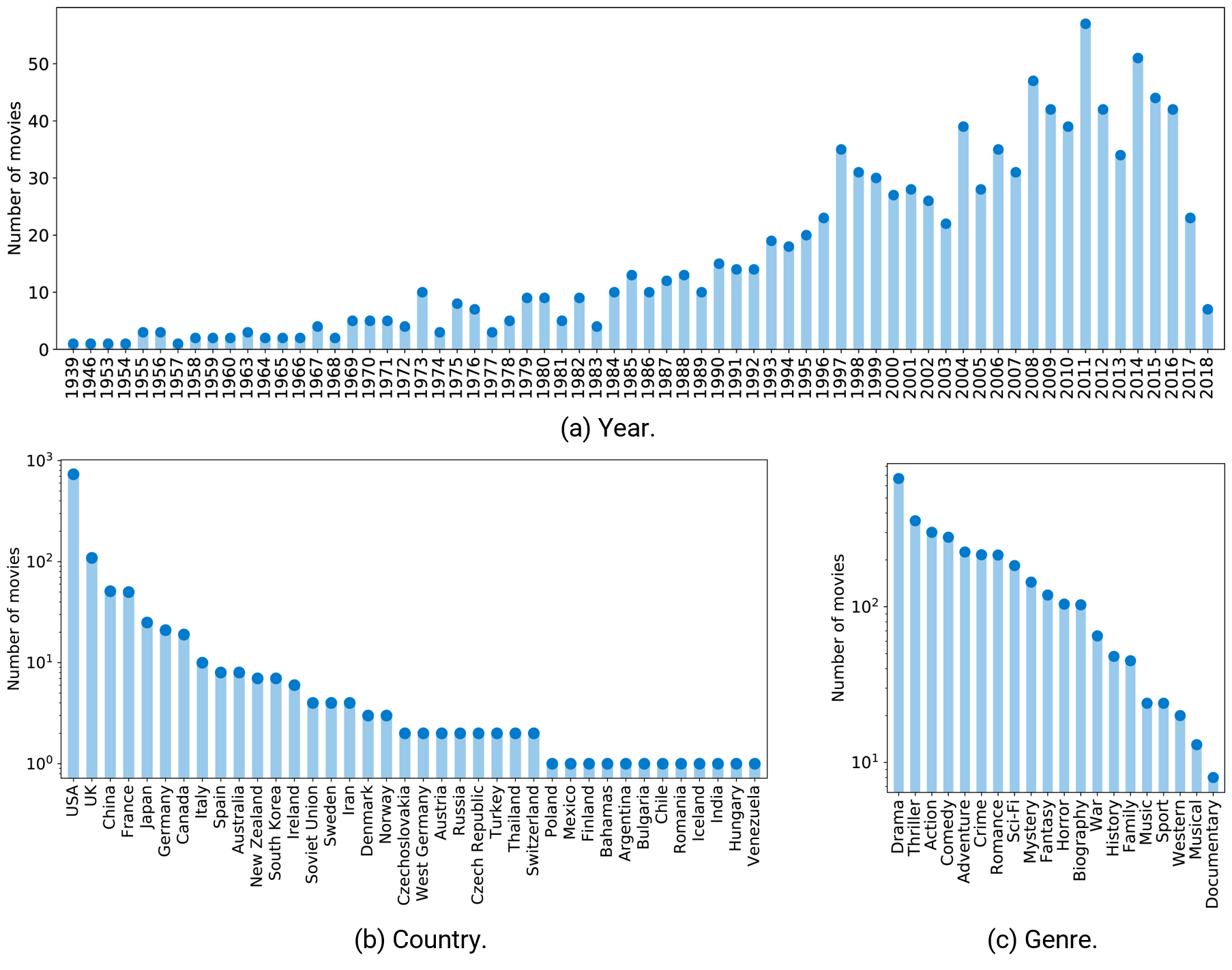
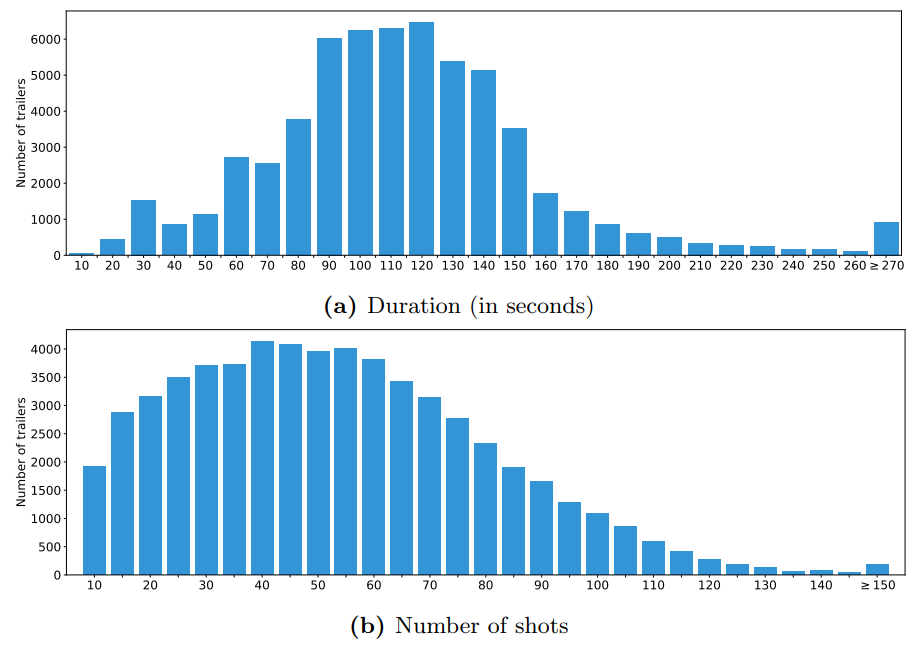
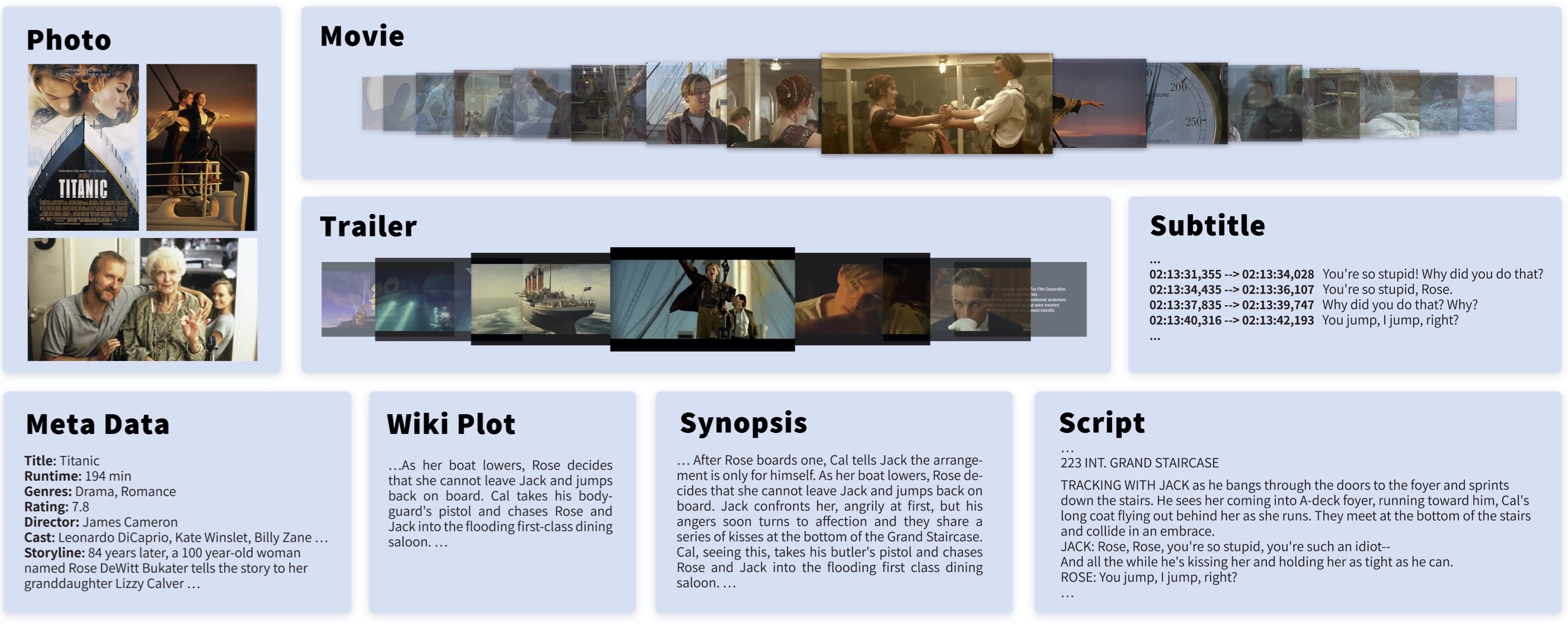
Data in MovieNet
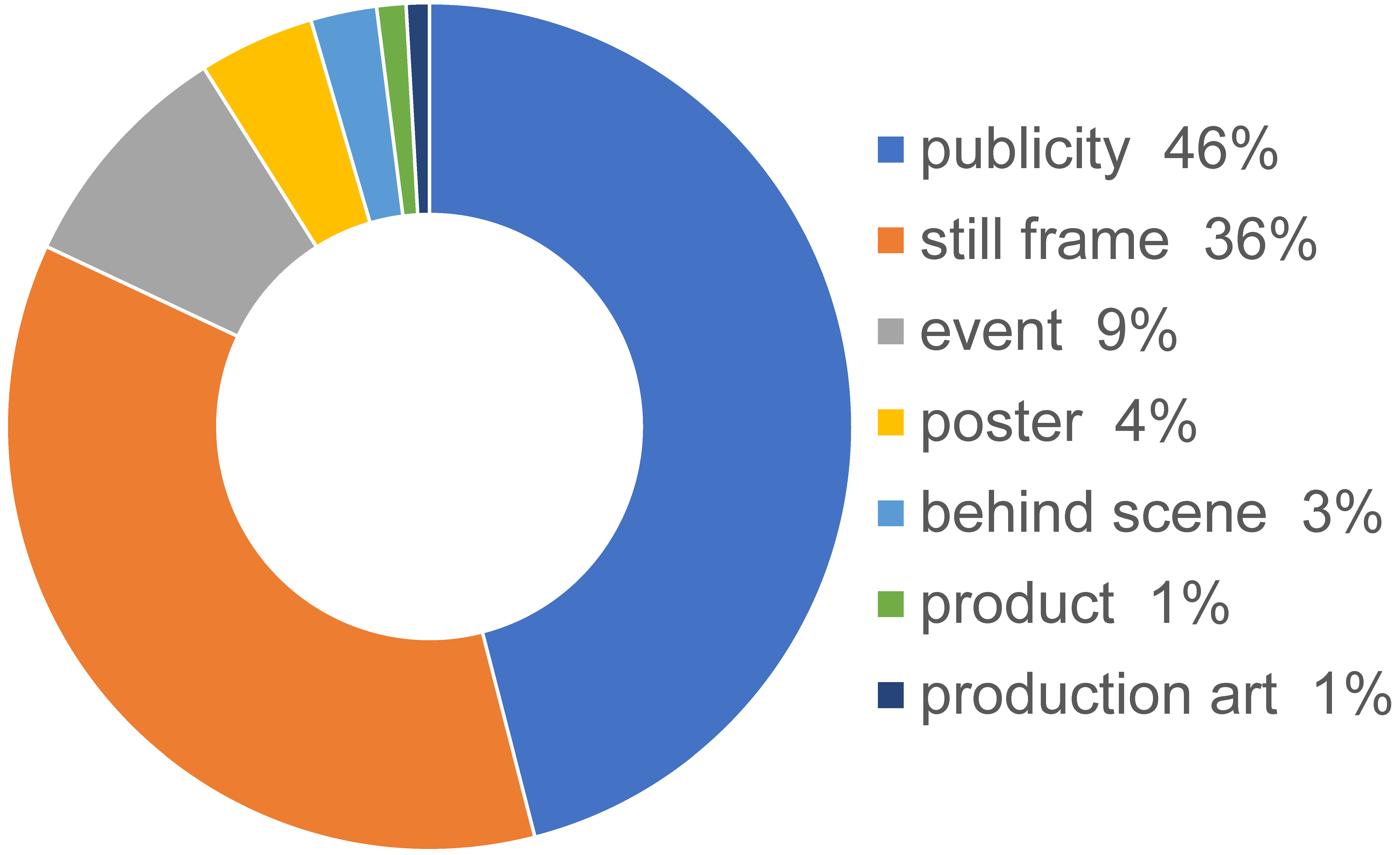
Annotation in MovieNet
Benchmarks
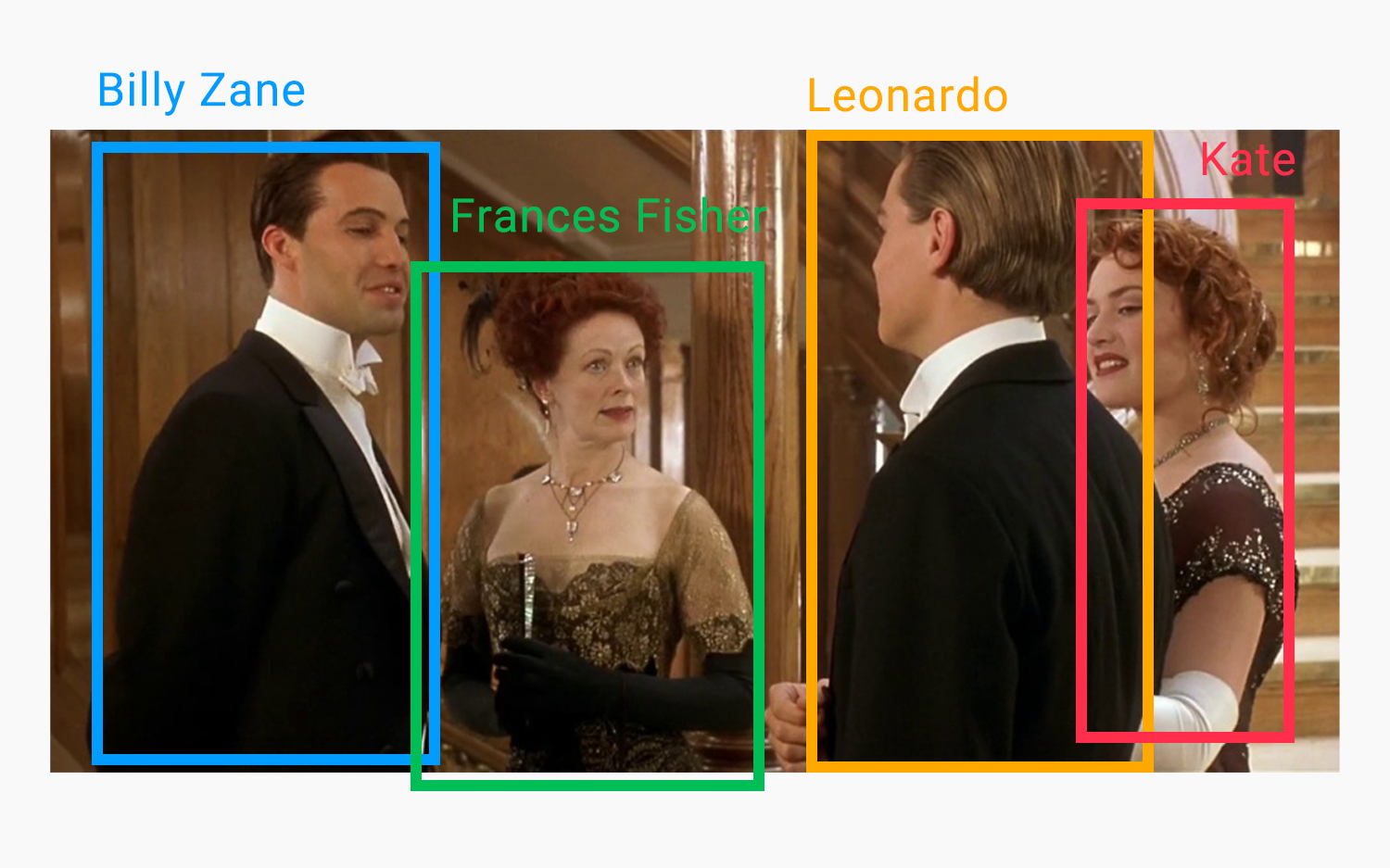




movienet-core contains multiple modules for processing
the dataset, including:
movienet-host is a flexiable MovieNet data manager
that help you deploy MovieNet data server remotely or locally.
movienet-tools, movienet, etc.
Download MovieNet
MovieNet Projects
Holistic Movie Understanding Dataset
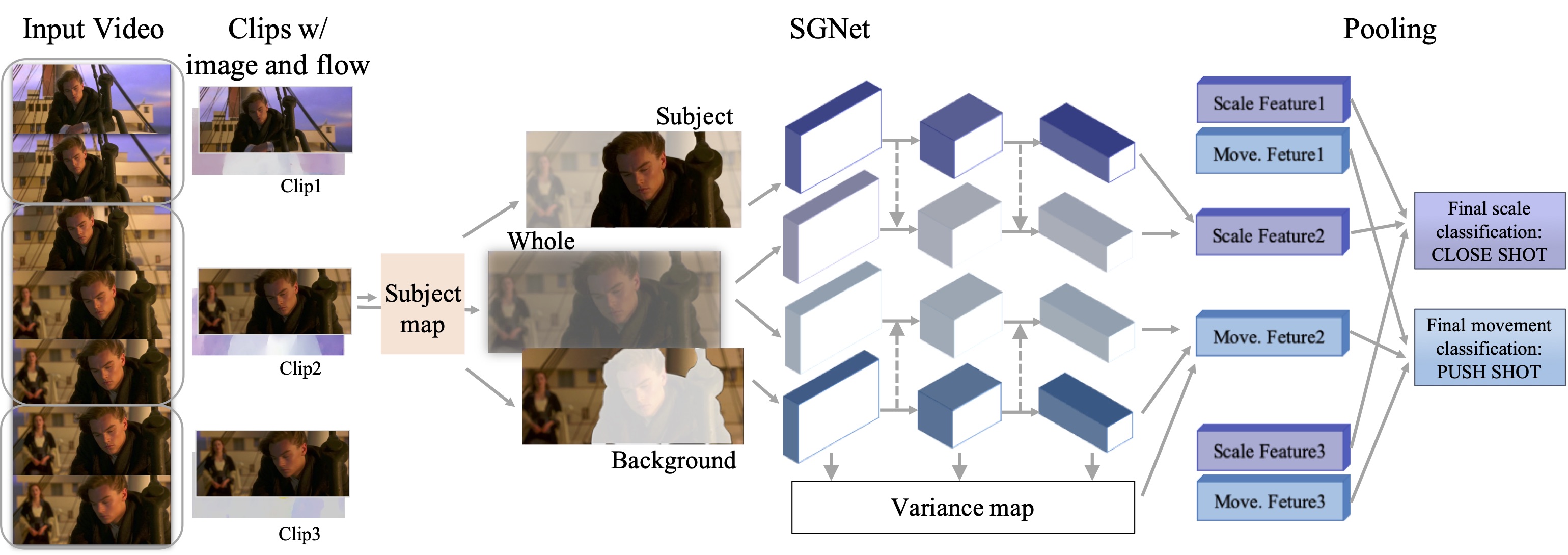
Movie Cinematic Style Analysis
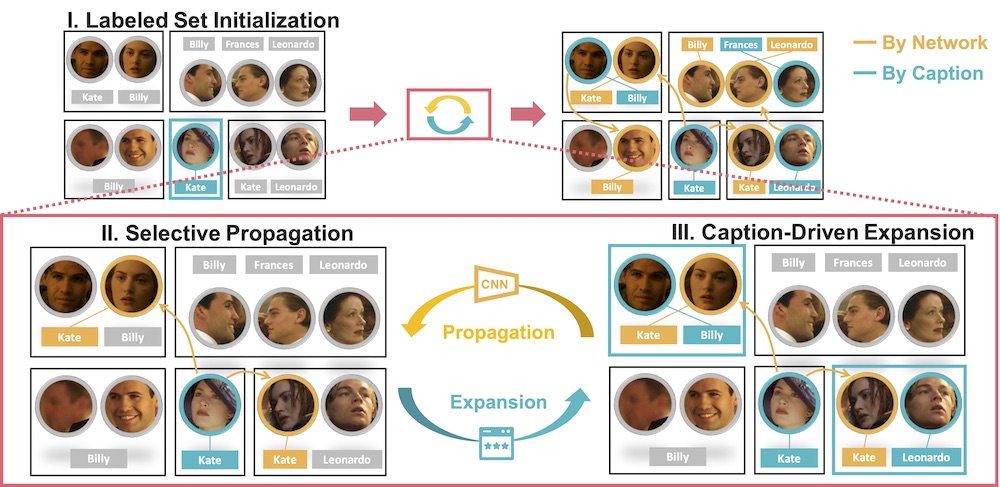
Unsupervised Face Recognition
Online Person Search

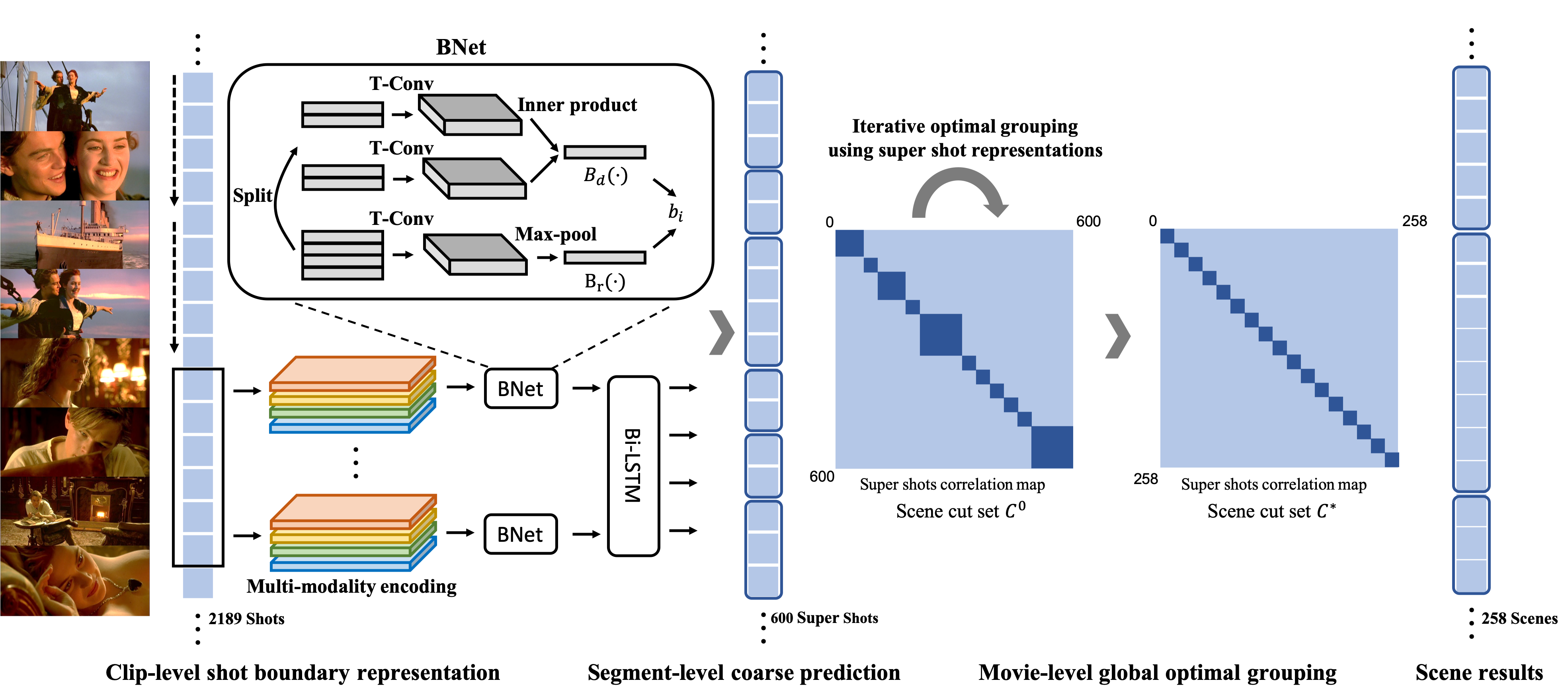
Movie Scene Temporal Segmentation
Movie Synopsis Association
Person Search

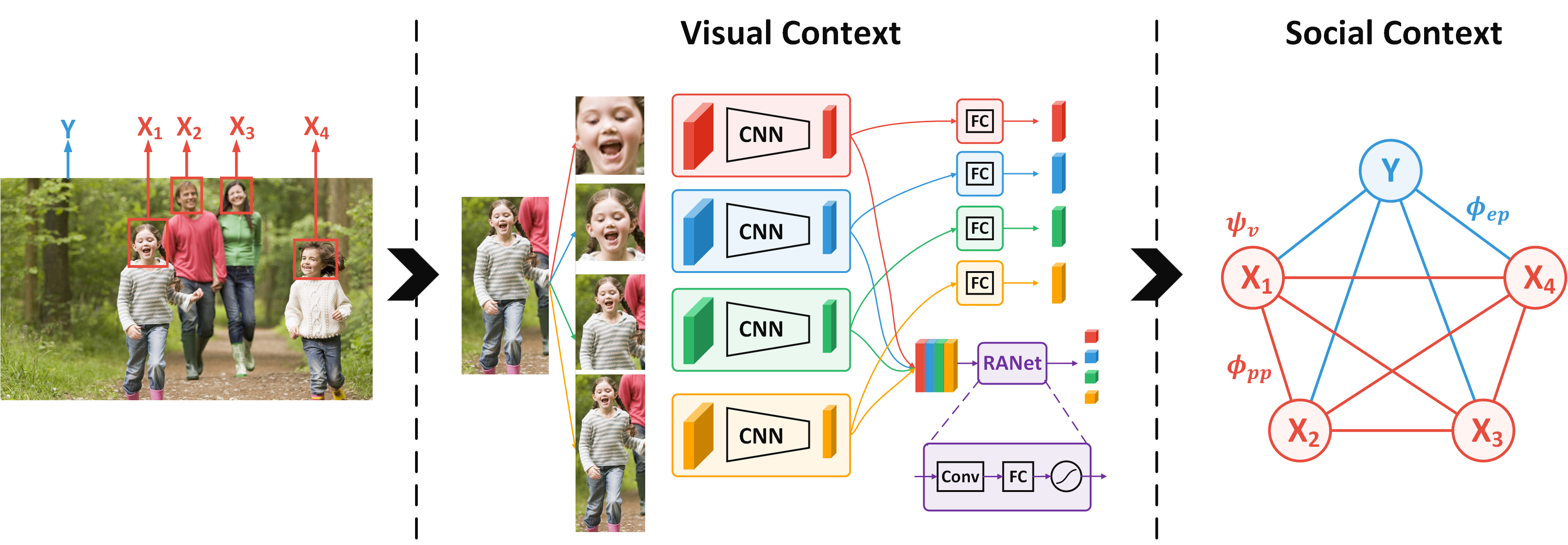
Person Recognition
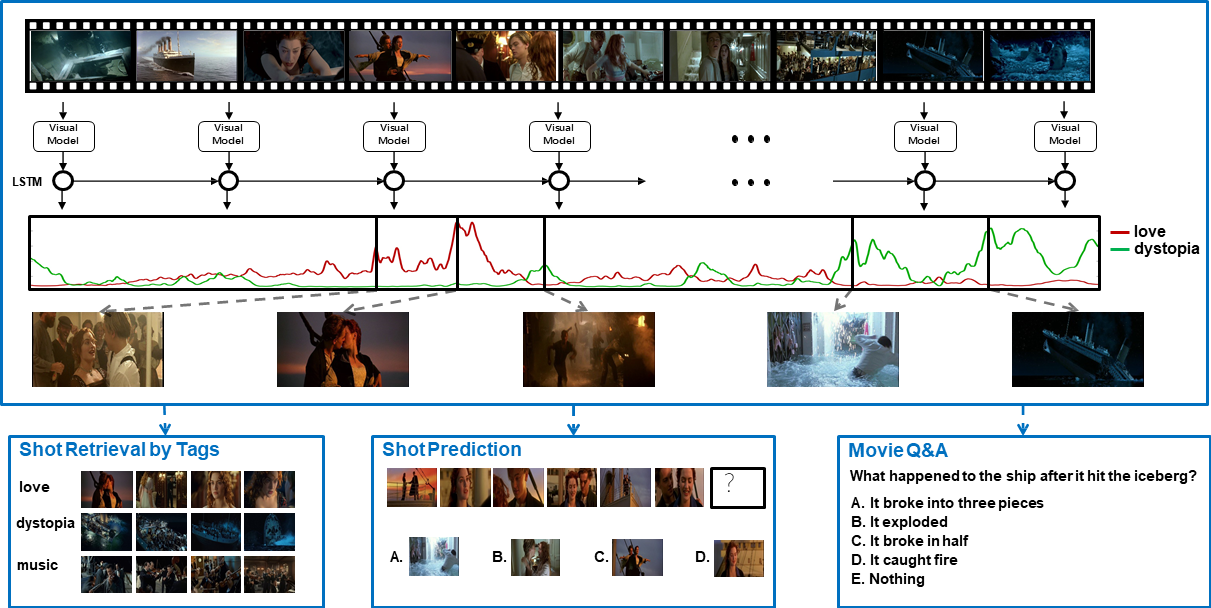
Trailer Analysis
News
movienet-tools
v0.0.1 is released.Contact Us
© 2020, OpenMMLab, by MMLab, CUHK. Last Update in July 2020.
@inproceedings{huang2020movienet,
title={MovieNet: A Holistic Dataset for Movie Understanding},
author={Huang, Qingqiu and Xiong, Yu and Rao, Anyi and Wang, Jiaze and Lin, Dahua},
booktitle = {The European Conference on Computer Vision (ECCV)},
year={2020}
}
@inproceedings{rao2020unified,
title={A Unified Framework for Shot Type Classification Based on Subject Centric Lens},
author={Rao, Anyi and Wang, Jiaze and Xu, Linning and Jiang, Xuekun and Huang, Qingqiu and Zhou, Bolei and Lin, Dahua},
booktitle = {The European Conference on Computer Vision (ECCV)},
year={2020}
}
@inproceedings{huang2020caption,
title={Caption-Supervised Face Recognition: Training a State-of-the-Art Face Model without Manual Annotation},
author={Huang, Qingqiu and Yang, Lei and Huang, Huaiyi and Wu, Tong and Lin, Dahua},
booktitle = {The European Conference on Computer Vision (ECCV)},
year={2020}
}
@inproceedings{xia2020online,
title={Online Multi-modal Person Search in Videos},
author={Xia, Jiangyue and Rao, Anyi and Xu, Linning and Huang, Qingqiu and Wen, Jiangtao and Lin, Dahua},
booktitle = {The European Conference on Computer Vision (ECCV)},
year={2020}
}
@inproceedings{rao2020local,
title={A Local-to-Global Approach to Multi-modal Movie Scene Segmentation},
author={Rao, Anyi and Xu, Linning and Xiong, Yu and Xu, Guodong and Huang, Qingqiu and Zhou, Bolei and Lin, Dahua},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10146--10155},
year={2020}
}
@InProceedings{Xiong_2019_ICCV,
author = {Xiong, Yu and Huang, Qingqiu and Guo, Lingfeng and Zhou, Hang and Zhou, Bolei and Lin, Dahua},
title = {A Graph-Based Framework to Bridge Movies and Synopses},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2019}
}
@inproceedings{huang2018person,
title={Person Search in Videos with One Portrait Through Visual and Temporal Links},
author={Huang, Qingqiu and Liu, Wentao and Lin, Dahua},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={425--441},
year={2018}
}
@InProceedings{Huang_2018_CVPR,
author = {Huang, Qingqiu and Xiong, Yu and Lin, Dahua},
title = {Unifying Identification and Context Learning for Person Recognition},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2018}
}
@article{huang2018trailers,
title={From Trailers to Storylines: An Efficient Way to Learn from Movies},
author={Huang, Qingqiu and Xiong, Yuanjun and Xiong, Yu and Zhang, Yuqi and Lin, Dahua},
journal={arXiv preprint arXiv:1806.05341},
year={2018}
}